Visual Effects
Using nerfies you can create fun visual effects. This Dolly zoom effect would be impossible without nerfies since it would require going through a wall.
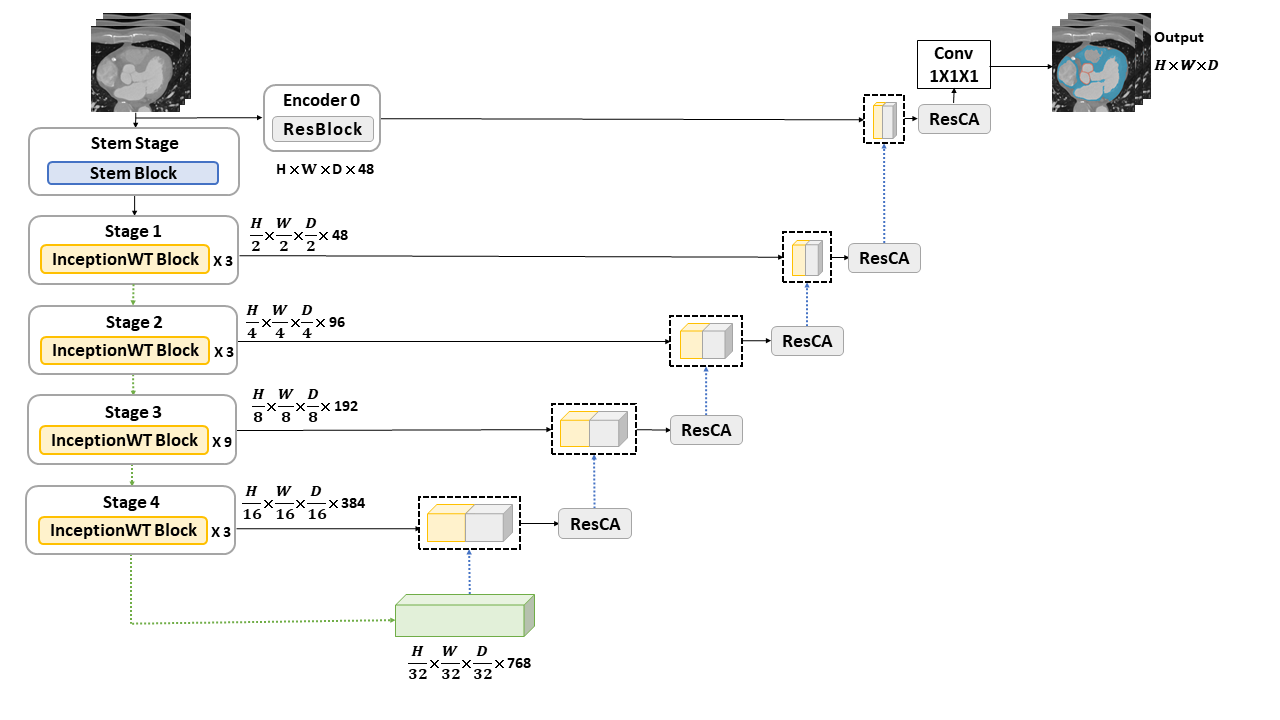
Due to complex cardiac anatomy and low image contrast, accurate segmentation of the myocardium and aortic valve in computed tomography (CT) images remains a major challenge. Current mainstream U-Net-based structures often lose high-frequency boundary information during continuous downsampling. To address this issue, this study proposes a new model WIC-Net, a novel dual-stream architecture that effectively preserves fine anatomical details. Regarding the model design, the encoder employs the InceptionWT block, which combines two branches: the spatial branch utilizes InceptionNeXt with large-kernel convolutions to capture global features, while the frequency branch adopts Wavelet Convolutions (WTConv). WTConv decomposes features via Discrete Wavelet Transform (DWT) and generates a frequency-aware attention map to further enhance the spatial features. The decoder integrates the Residual Coordinate Attention (ResCA) block to progressively refine feature representations and accurately guide spatial reconstruction. This strategy not only effectively recovers micro-structures but also ensures precise boundary delineation. This study evaluated the proposed model using five-fold cross-validation on both the M-WHS 2025 and MM-WHS datasets. Experimental results show that WIC-Net achieves superior performance compared to existing state-of-the-art models across several key metrics, demonstrating remarkable advantages particularly in the segmentation of small structures. This fully proves its highly accurate segmentation capabilities for clinical applications.
Using nerfies you can create fun visual effects. This Dolly zoom effect would be impossible without nerfies since it would require going through a wall.
As a byproduct of our method, we can also solve the matting problem by ignoring samples that fall outside of a bounding box during rendering.
We can also animate the scene by interpolating the deformation latent codes of two input frames. Use the slider here to linearly interpolate between the left frame and the right frame.
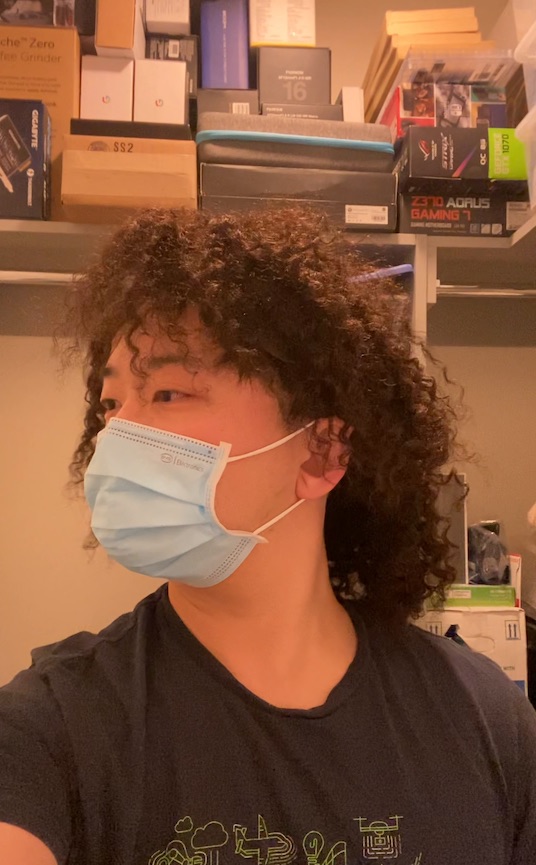
Start Frame
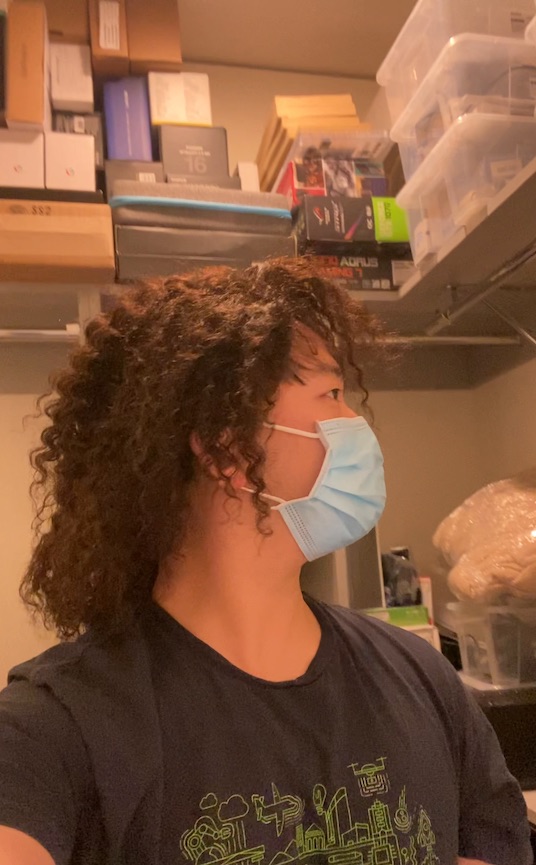
End Frame
Using Nerfies, you can re-render a video from a novel viewpoint such as a stabilized camera by playing back the training deformations.
There's a lot of excellent work that was introduced around the same time as ours.
Progressive Encoding for Neural Optimization introduces an idea similar to our windowed position encoding for coarse-to-fine optimization.
D-NeRF and NR-NeRF both use deformation fields to model non-rigid scenes.
Some works model videos with a NeRF by directly modulating the density, such as Video-NeRF, NSFF, and DyNeRF
There are probably many more by the time you are reading this. Check out Frank Dellart's survey on recent NeRF papers, and Yen-Chen Lin's curated list of NeRF papers.
@article{park2021nerfies,
author = {Park, Keunhong and Sinha, Utkarsh and Barron, Jonathan T. and Bouaziz, Sofien and Goldman, Dan B and Seitz, Steven M. and Martin-Brualla, Ricardo},
title = {Nerfies: Deformable Neural Radiance Fields},
journal = {ICCV},
year = {2021},
}